SQL基础:解析SQL Server CDC配合Kafka Connect监听数据变化的问题
时间:2024-02-08 11:17作者:下载吧人气:38
写在前面
好久没更新Blog了,从CRUD Boy转型大数据开发,拉宽了不少的知识面,从今年年初开始筹备、组建、招兵买马,到现在稳定开搞中,期间踏过无数的火坑,也许除了这篇还很写上三四篇。
进入主题,通常企业为了实现数据统计、数据分析、数据挖掘、解决信息孤岛等全局数据的系统化运作管理 ,为BI、经营分析、决策支持系统等深度开发应用奠定基础,挖掘数据价值 ,企业会开始着手建立数据仓库,数据中台。而这些数据来源则来自于企业的各个业务系统的数据或爬取外部的数据,从业务系统数据到数据仓库的过程就是一个ETL(Extract-Transform-Load)行为,包括了采集、清洗、数据转换等主要过程,通常异构数据抽取转换使用Sqoop、DataX等,日志采集Flume、Logstash、Filebeat等。
数据抽取分为全量抽取和增量抽取,全量抽取类似于数据迁移或数据复制,全量抽取很好理解;增量抽取在全量的基础上做增量,只监听、捕捉动态变化的数据。如何捕捉数据的变化是增量抽取的关键,一是准确性,必须保证准确的捕捉到数据的动态变化,二是性能,不能对业务系统造成太大的压力。
增量抽取方式
通常增量抽取有几种方式,各有优缺点。
1. 触发器
在源数据库上的目标表创建触发器,监听增、删、改操作,捕捉到数据的变更写入临时表。
优点:操作简单、规则清晰,对源表不影响;
缺点:对源数据库有侵入,对业务系统有一定的影响;
2. 全表比对
在ETL过程中,抽取方建立临时表待全量抽取存储,然后在进行比对数据。
优点:对源数据库、源表都无需改动,完全交付ETL过程处理,统一管理;
缺点:ETL效率低、设计复杂,数据量越大,速度越慢,时效性不确定;
3. 全表删除后再插入
在抽取数据之前,先将表中数据清空,然后全量抽取。
优点:ETL 操作简单,速度快。
缺点:全量抽取一般采取T+1的形式,抽取数据量大的表容易对数据库造成压力;
4. 时间戳
时间戳的方式即在源表上增加时间戳列,对发生变更的表进行更新,然后根据时间戳进行提取。
优点:操作简单,ELT逻辑清晰,性能比较好;
缺点:对业务系统有侵入,数据库表也需要额外增加字段。对于老的业务系统可能不容易做变更。
5. CDC方式
变更数据捕获Change Data Capture(简称CDC),SQLServer为实时更新数据同步提供了CDC机制,类似于Mysql的binlog,将数据更新操作维护到一张CDC表中。开启CDC的源表在插入INSERT、更新UPDATE和删除DELETE活动时会插入数据到日志表中。cdc通过捕获进程将变更数据捕获到变更表中,通过cdc提供的查询函数,可以捕获这部分数据。详情可以查看官方介绍:关于变更数据捕获 (SQL Server)
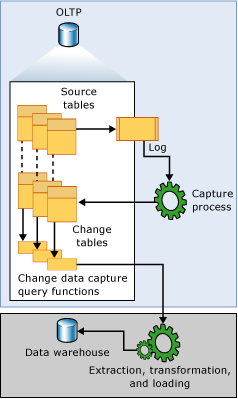
优点:提供易于使用的API 来设置CDC 环境,缩短ETL 的时间,无需修改业务系统表结构。
缺点:受数据库版本的限制,实现过程相对复杂。
CDC增量抽取
先决条件
1. 已搭建好Kafka集群,Zookeeper集群;
2. 源数据库支持CDC,版本采用开发版或企业版。
案例环境:
Ubuntu 20.04
Kafka2.13-2.7.0
Zookeeper 3.6.2
SQL Server 2012
步骤
除了数据库开启CDC支持以外,主要还是要将变更的数据通过Kafka Connect传输数据,Debezium是目前官方推荐的连接器,它支持绝大多数主流数据库:MySQL、PostgreSQL、SQL Server、Oracle等等,详情查看Connectors。
1. 数据库步骤
开启数据库CDC支持
在源数据库执行以下命令:
EXEC sys.sp_cdc_enable_db GO
附上关闭语句:
exec sys.sp_cdc_disable_db
查询是否启用
select * from sys.databases where is_cdc_enabled = 1
相关推荐
相关下载
热门阅览
- 1SQL开发知识:MyBatis SQL xml处理小于号与大于号正确的格式
- 2SQL基础:SQLServer2019 数据库的基本使用之图形化界面操作的实现
- 3一文教你SQL Server2012的数据库备份和还原的教程
- 4SQL异常:教你sqlserver连接错误之SQL评估期已过的问题解决方法
- 5SQL基础:SQL Server的全文搜索功能
- 6SQL开发知识:SQL中Truncate的用法
- 7数据库恢复之 delete误删数据使用SCN号恢复的详细方希
- 8SQL报错:由于系统错误 126 (SQL Server),指定驱动程序无法加载问题的处理
- 9SQL开发知识:SQL Server数据库查找表名或列名中包含空格的表和列
- 10SQL开发知识:SQL Server执行动态SQL的正确方法
- 11Navicat 如何连接SQLServer数据库详细步骤截图
- 12SQL开发知识:关于SQL Server数据库触发器详解
最新排行
- 1SQL开发知识:SQL注入工具
- 2SQL开发知识:SQL 在自增列插入指定数据的操作方法
- 3Sql Server2012数据库使用IP登录服务器的配置教程
- 4SQL开发知识:Navicat导出.sql文件方法
- 5SQL开发知识:SQL Server表和索引存储结构
- 6SQL开发知识:Sql注入原理简介
- 7SQL开发知识:SQL Server Management Studio(SSMS)复制数据库的方法
- 8SQL开发知识:SQL Server执行动态SQL的正确方法
- 9SQL开发知识:SQL Server Parameter Sniffing及其改进方法
- 10SQL开发知识:sql server2008调试存储过程的步骤
- 11SQL开发知识:SQL Server非动态 SQL语句来对动态查询进行执行
- 12一文带你详解SQL Server 2016数据库快照代理过程

网友评论